How dlt works
dlt automatically turns JSON returned by any source
(e.g. an API) into a live dataset stored in the
destination of your choice (e.g. Google BigQuery). It
does this by first extracting the JSON data, then
normalizing it to a schema, and finally loading
it to the location where you will store it.
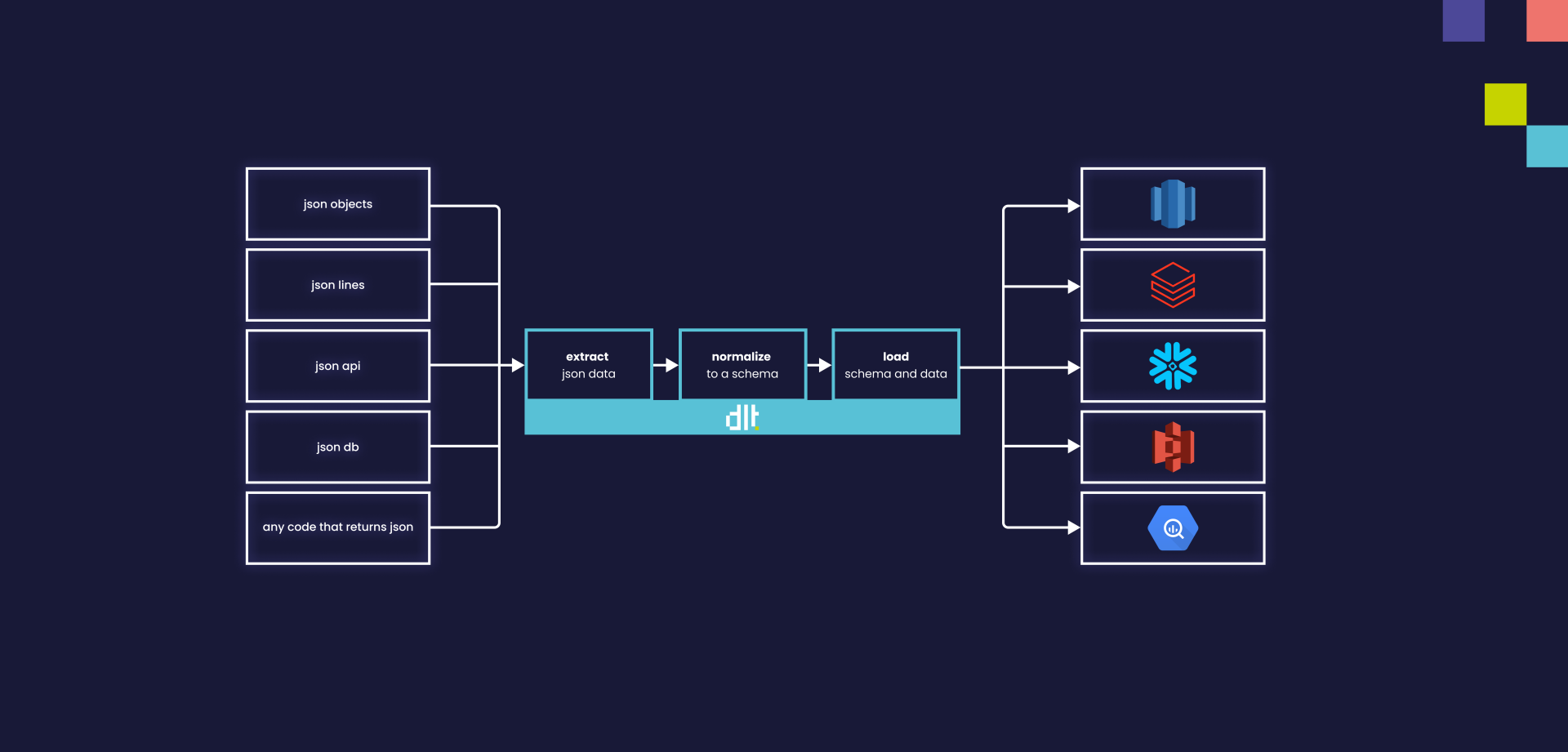
Extract
The Python script requests data from an API or a similar
source. Once this data is received, the script parses the
JSON and provides it to dlt as input, which then normalizes that data.
Normalize
The configurable normalization engine in dlt recursively unpacks this nested structure into
relational tables (i.e. inferring data types, linking tables to create nested relationships,
etc.), making it ready to be loaded. This creates a
schema, which will automatically evolve to any future
source data changes (e.g. new fields or tables).
Load
The data is then loaded into your chosen destination.
dlt uses configurable, idempotent, atomic loads that ensure data safely ends up there. For
example, you don't need to worry about the size of the data you are loading and if the process is
interrupted, it is safe to retry without creating errors.